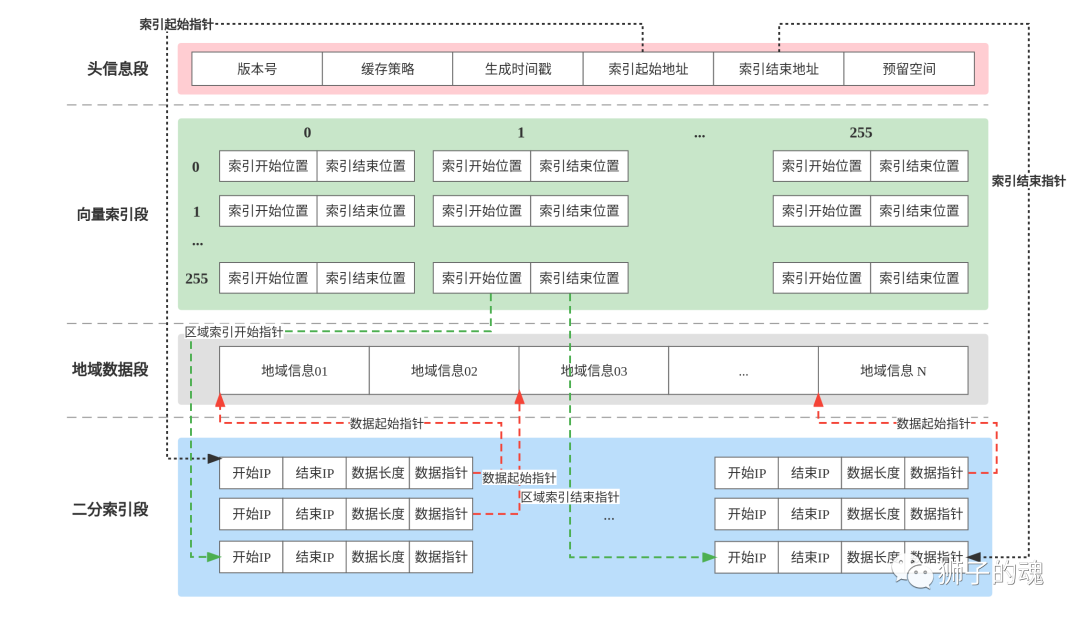
XDB存储管理格式已经稳定且测试效果非常好,不仅可以支持亿级别的IP数据段,还将查询时间缩短到了10微秒级别,代码和使用文档请到Github或者Gitee浏览,这里主要介绍xdb数据格式的结构。
整个结构按照文件指针从小到大分为如下四个层段:
| Header 数据段 | Vector 索引数据段 | 地域信息数据段 | 二分索引数据段 |
| 256 Bytes | 512 KiB | 动态空间 | 动态空间 |
一,第一层Header段
header段主要是记载一些头信息,这个段固定占据256字节的空间,目前实际上只用到16字节,剩下的全部为0x00的预留空间,便于后期扩展需要,目前的具体空间使用情况如下:
| 版本号 | 缓存策略 | 文件生成时间 | 索引起始地址 | 索引结束地址 | IP版本 | 指针字节数 | 剩余空间 |
| 2 Bytes | 2 Bytes | 4 Bytes | 4 Bytes | 4 Bytes | 2 Bytes | 2 Bytes | 236Bytes |
题外思考,有哪些可能的空间扩展需求呢?例如:
1. 如果想要验证xdb数据的完整性,可以剩余的未占据的字节中存储 header 段外的数据的 MD5 哈希值,便于确认文件是否在网络传输或者项目打包过程中受损。
2. 增加其他的加速查询的信息等等。
二,第二层vector索引段
vector索引段是二分索引的二级索引,本质上是一个256 × 256的二维数组,等同于将全部的IP数据段按照IP的前两个字节拆分成256 × 256个分区,这样利用一次固定IO操作就可以很大程度的减少后续的二分查找的IO操作次数,数据行数越多,这个索引的加速效果越明显;对于仓库的默认数据,我做过统计大部分的IP查询可以使用仅仅两次IO操作完成整个查询,vector索引空间表结构如下:
| 0 | 1 | ... | 254 | 255 |
| 1 | ||||
| 2 | ||||
| ... | ||||
| 254 | ||||
| 255 |
如图所示,本质上就是一个256 × 256的二维数组,每个vector索引项的结构,也就是上面的256 × 256的每个单元格的结构如下:
| 区域索引开始位置 | 区域索引结束位置 |
| 4 Bytes | 4 Bytes |
开始位置指向区域二分索引的开始位置,结束位置指向区域二级索引的结束位置,也就是vector索引将整个二分索引分成了256 × 256个分区,便于更快的减少二分索引的查找范围,从而加速查询。每个单元格的空间是固定的,所以整个vector索引段占据的空间为:256 × 256 × 8 = 524288 Bytes = 512 KiB,这个空间是固定的与原始的IP数据行数无关。
三,第三层地域信息段
原始数据的标准格式为开始IP|结束IP|地域信息,这层写入的是原始数据中的地域信息,对于xdb格式,你可以完全替换为自己的地域信息,原始文件是什么xdb里面就存储什么,例如你可以设置为JSON格式存储不同语言的定位信息等等。
1,例如如下三个连续的IPv4数据段:
0.0.0.0|0.255.255.255|0|0|内网IP|内网IP 1.0.0.0|1.0.0.255|澳大利亚|0|0|0 1.0.1.0|1.0.3.255|中国|福建省|福州市|电信
会依次写入如下三个连续的地域信息:
0|0|内网IP|内网IP 澳大利亚|0|0|0 中国|福建省|福州市|电信
2,例如如下的三个连续的IPv6数据段:
2401:b180:2800::|2401:b180:28ff:ffff:ffff:ffff:ffff:ffff|中国|上海|上海市|阿里云 2401:b180:2900::|2401:b180:2fff:ffff:ffff:ffff:ffff:ffff|中国|北京|北京市|阿里云 2401:b180:3000::|2401:b180:30ff:ffff:ffff:ffff:ffff:ffff|中国|广东省|深圳市|阿里云
会依次写入如下三个连续的地域信息:
中国|上海|上海市|阿里云 中国|北京|北京市|阿里云 中国|广东省|深圳市|阿里云
原始文件中的地域信息是什么就会写入什么,字符串使用的是utf-8编码,生成程序会自动去重,同样的地域信息只会写入一份,写入前会记载当时文件的指针存储到下面的二分索引的数据指针空间中,所以这一层的空间占用是没法确定的,最终写入了多少数据就占据多少空间。
四,第四层二分索引空间段
二分索引层是查询的核心,搜索过程的核心就是在二分索引中进行拆半查找,二分索引的空间表结构如下:
| 二分索引 01 | 二分索引 02 | ... | 二分索引 N |
| $fixed Bytes | $fixed Bytes | $fixed Bytes | $fixed Bytes |
每个二分索引项 IPv4 占据固定的$fixed = 14字节,IPv6 占据固定的 $fixed = 38字节,详细字段和空间分布如下:
1,IPv4二分索引项空间结构,即14 = 4 + 4 + 2 + 4:
| 开始 IP | 结束 IP | 数据长度 | 数据指针 |
| 4 Bytes | 4 Bytes | 2 Bytes | 4 Bytes |
2,IPv6二分索引项空间结构,即38 = 16 + 16 + 2 + 4:
| 开始 IP | 结束 IP | 数据长度 | 数据指针 |
| 16 Bytes | 16 Bytes | 2 Bytes | 4 Bytes |
所以二分索引的空间占用也是没法确定,但是可以通过原始的IP数据段行数来计算,例如默认的data/ipv4_source.txt原始数据有683591行,则二分索引空间占用为:683591 × 14 = 9570274 Bytes = 9.12 MiB,占据了11MiB的整个data/ip2region_v4.xdb的绝大部分空间,这个二分索引空间是还可以继续压缩的,我现在的原则是查询速度第一,空间压缩这块暂时还没有这个必要,有兴趣的的小伙伴可以尝试自己去压缩下。
压缩的尝试思路如下:
1,索引项的尾首合一:如果能确保二分索引项的连续,则下一个索引项的开始IP可以通过上一个索引项的结束IP计算得出,这样每个索引项可以去掉一个固定的IP地址空间占用,会极大的减少 xdb 文件的空间占用。
2,弹性指针:目前 xdb 内部的指针固定的使用4字节,对于小文件可以使用更小字节数的指针从而减小文件空间的占用。
五、XDB结构层级关系
整个xdb文件的空间结构以及层级之间的大致关系描述如下图所示: